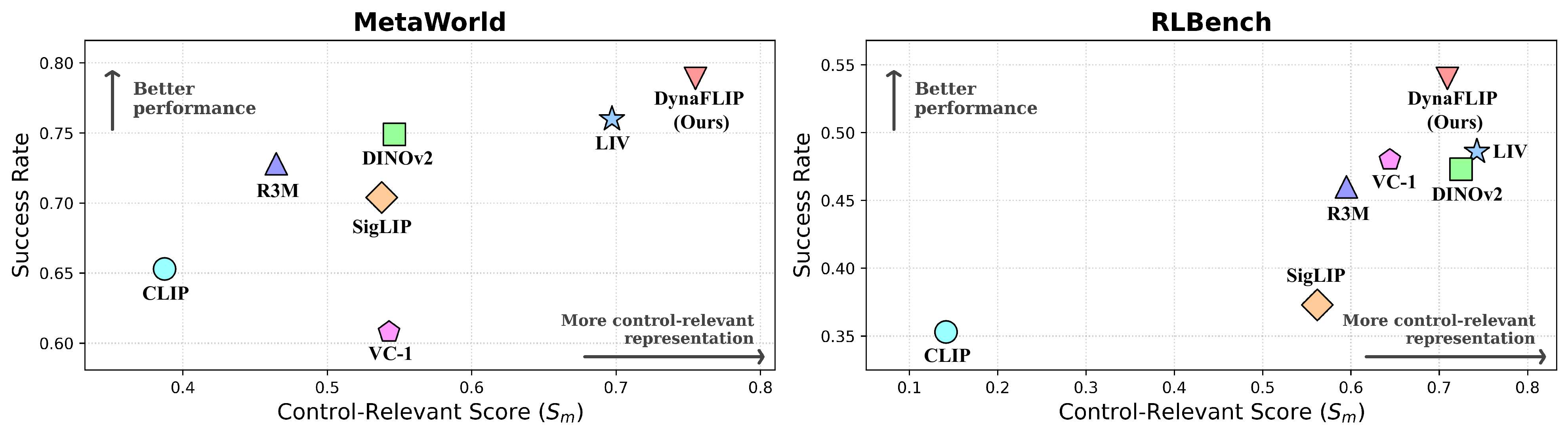
TL;DR: [one-sentence summary of DynaFLIP goes here]

Robot manipulation critically depends on perception that preserves the action-relevant aspects of a scene. Yet most robot learning pipelines are built upon visual encoders pre-trained for static recognition or vision-language alignment, leaving motion understanding to downstream policies. We introduce DynaFLIP, a dynamics-aware multimodal pre-training framework that pushes motion understanding upstream into perception. We construct image–language–3D flow triplets from heterogeneous human and robot videos, and use these triplets as training-time supervision to shape an image-only encoder. Our key idea is to encourage the three modalities to span a small simplex volume in the shared hyperspherical space—a smaller simplex volume indicating stronger alignment. To avoid the geometric ambiguity and trivial collapse of naive volume minimization, we combine simplex-volume minimization with a cosine regularizer and a contrastive objective. Our analyses show that DynaFLIP focuses on control-relevant regions critical for manipulation. The resulting dynamics-aware representations serve as reusable visual backbones and consistently outperform baselines across diverse downstream policies, including VLAs. We validate this across diverse simulation and real-world setups, with gains reaching +22.5% under out-of-distribution scenarios. Our results suggest that robot generalization improves when visual representations are trained to encode not just what is present, but how the world changes under action.
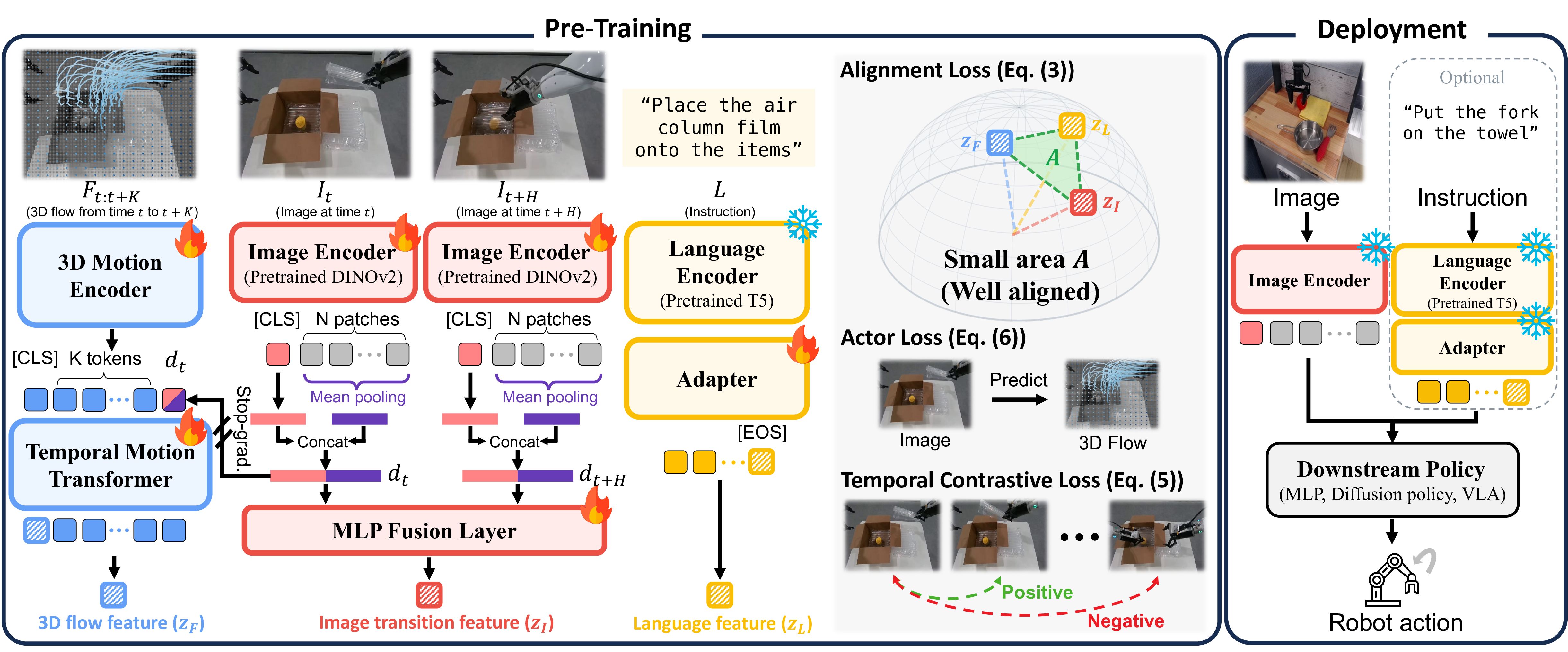
Higher control-relevant score Sm (x-axis) correlates with higher manipulation success rate (y-axis). DynaFLIP sits at the top-right of both plots — its dynamics-aware representations preserve control-relevant information and improve manipulation performance.
DynaFLIP produces more spatially coherent and object-aware feature structures than the baselines.
Original
DINOv2
SigLIP
DynaFLIP
Feature visualization with PCA
DynaFLIP attends to control-relevant regions (i.e., manipulated objects and interaction regions), whereas baselines distribute attention over less relevant areas such as the background or irrelevant objects.
Original
DINOv2
SigLIP
DynaFLIP
Grad-CAM heatmaps over action prediction
DynaFLIP outperforms baseline image encoders on real-world manipulation when used with a Vision-Language-Action model (π0.5).
| Image Encoder |
Real-World Manipulation | |||
|---|---|---|---|---|
| Pick <object> into Sink | Pour almonds into <object> | Unfold Towel | Mean | |
| DINOv2 | 75 | 65 | 40 | 60.0 |
| SigLIP | 55 | 60 | 20 | 45.0 |
| DynaFLIP | 90 | 70 | 50 | 70.0 |
On the LIBERO benchmark with Diffusion Policy, DynaFLIP consistently outperforms baselines in both frozen and LoRA fine-tuned settings.
| Image Encoder |
Language Encoder |
Frozen | LoRA Fine-tuned | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 90 | Goal | Object | Spatial | Long | Mean | 90 | Goal | Object | Spatial | Long | Mean | ||
| DINOv2 | CLIP | 14.4 | 75.0 | 33.5 | 42.5 | 20.5 | 37.2 | 83.6 | 77.5 | 82.0 | 81.0 | 67.5 | 78.3 |
| SigLIP | SigLIP | 24.3 | 54.5 | 13.0 | 52.0 | 8.5 | 30.5 | 82.6 | 80.5 | 82.0 | 74.0 | 76.5 | 79.1 |
| DynaFLIP | DynaFLIP | 31.7 | 70.5 | 37.5 | 51.5 | 16.5 | 41.5 | 78.1 | 84.5 | 83.5 | 78.5 | 80.5 | 81.0 |
A lightweight three-layer MLP policy ensures that downstream performance reflects representation quality rather than policy capacity. DynaFLIP achieves the highest success rates on both MetaWorld and RLBench.
MetaWorld
| Algorithm | Easy (7) | Medium (5) | Hard & Very Hard (3) | Mean |
|---|---|---|---|---|
| DINOv2 | 77.7 | 77.6 | 64.0 | 74.9 |
| SigLIP | 74.3 | 72.8 | 56.7 | 70.4 |
| DynaFLIP | 81.1 | 81.6 | 69.3 | 78.9 |
RLBench
| Algorithm | close box | put rubbish in bin | close laptop lid | water plants | unplug charger | toilet seat down | Mean |
|---|---|---|---|---|---|---|---|
| DINOv2 | 84 | 12 | 76 | 4 | 24 | 84 | 47.3 |
| SigLIP | 80 | 4 | 52 | 0 | 12 | 76 | 37.3 |
| DynaFLIP | 88 | 8 | 76 | 20 | 36 | 96 | 54.0 |
| Image Encoder |
Visual, spatial perturbations | Semantic perturbations | Mean |
|---|---|---|---|
| DINOv2 | 17.5 | 27.5 | 22.5 |
| SigLIP | 25.0 | 30.0 | 27.5 |
| DynaFLIP | 40.0 | 75.0 | 57.5 |
DynaFLIP's focus on control-relevant regions enables it to remain robust to changes in object layout and the presence of distractors.
DynaFLIP incorporates language as one of its pre-training modalities and learns to align visual changes with task-relevant instructions, yielding representations that remain robust under unseen objects and instructions.
@inproceedings{TODO_bibkey,
author = {TODO and Lee, Jusuk and TODO},
title = {TODO: Paper Title},
booktitle = {TODO: Venue},
year = {YYYY},
}